Cybersecurity and Artificial Intelligence: Challenges & Solutions
1. AI and its vulnerabilities
The meteoric rise of artificial intelligence is now a phenomenon of considerable magnitude, evolving at a remarkable speed. From the “Siri” voice assistant on our smartphones to the chatbot “ChatGPT” to the facial recognition used to unlock our electronic devices, artificial intelligence permeates our daily lives in a ubiquitous way, providing extraordinary ease of use and power. Who doesn’t use “ChatGPT” to write complex messages these days?
However, as Spider-Man’s late uncle, Ben Parker, pointed out, “With great power comes great responsibility!” Indeed, while AI is a revolutionary and powerful creation, it comes with considerable responsibility. It is imperative to guarantee its security, an area that differs greatly from what we are used to today in the world of computing.
Why the Security Problem Arises in AI
The flaws in artificial intelligence systems differ significantly from those that can be encountered in more traditional systems, often caused by “bugs” or human error. Attacks on AI, also known as AI attacks, instead target vulnerabilities resulting from inherent limitations in algorithms, which, for now, remain difficult to reduce.
A study conducted by Adversa researchers sheds light on vulnerable areas being exploited to attack AI-powered systems. According to their findings, it is mainly systems that process visual data that account for the majority of attack targets in the field of AI.
Vulnerable fields
Attack Scenarios
Attacks against artificial intelligence systems, commonly known as adversarial attacks, as described by the UC Berkeley Machine Learning team, rely on the creation of illusions. These are manipulative actions and deceptive data designed to fool the AI algorithm, causing the machine to behave unusually or revealing confidential information.
The way these attacks work differs from conventional software, as AI systems use machine learning algorithms that develop their behavior through repetitive actions and experience. The problem in terms of security lies in the fact that these algorithms transform an input data into an output data. For example, if an AI system recognizes that an image contains a specific object by comparing the pixels in that image with those of other images of the processed object during its training, this feature can be exploited to confuse the algorithm.
The following are some examples of attacks targeting the areas of vulnerability discussed above.
- Adversarial attack on vision systems:
In 2018, a group of researchers successfully tricked an autonomous driving system into identifying a stop sign as a speed limit sign. The method used was to manipulate the image of the STOP sign by adding pixels, thus creating a disturbance invisible to the naked eye.

Detected STOP at 57.7%
+ .007 x

=
Detected Speed limit sign 50 to 99. 3%
This is how the GoogLeNet image classifier was misled, thinking that an image clearly depicting a STOP sign corresponded to a 50 speed limit sign, according to its perspective.
- Adversarial attack on speech recognition systems
Adversarial attacks are not limited to vision systems. In 2018, researchers demonstrated that automated speech recognition (ASR) systems could also be the target of such attacks.
ASR is the technology that allows devices such as Amazon Alexa, Apple Siri, and Microsoft Cortana to analyze voice commands.
In this type of attack, an attacker manipulates an audio file in order to embed a hidden voice command that is inaudible to the human ear. So a human auditor wouldn’t notice the change, but for a machine learning algorithm, the change would be clearly detectable and actionable. This technique could be used to secretly transmit commands to smart speakers.
- Adversarial attack on text classifiers
In 2019, researchers from IBM Research, Amazon, and the University of Texas demonstrated that these types of attacks also target text classifiers’ machine learning algorithms, such as spam filters.
Dubbed “paraphrasing attacks,” these text-based adversarial attacks involve making changes to word sequences in a piece of text in order to cause a misclassification in the machine learning algorithm.
- Black-box and white-box adversarial attack
Like any cyberattack, the success of adversarial attacks depends on how much information an attacker has about the targeted machine learning system. Depending on the level of information held, a distinction is made between black-box and white-box attacks.
An attack is referred to as a black-box when the attacker has limited information and access, thus equivalent to the capabilities of an ordinary user. In addition, the attacker has no knowledge of the system or the data underlying the service. For example, to target a publicly available API like Amazon Rekognition, the attacker must probe the system by providing various inputs repeatedly and evaluate the responses until a vulnerability is discovered.
A white-box attack is when the attacker has complete knowledge and transparency of the target system or data. In this case, attackers can examine the inner workings of the system and are in a better position to identify vulnerabilities.
Chen, a researcher, pointed out that “black-box attacks are more convenient for assessing the robustness of deployed and limited-access machine learning systems from an adversary’s perspective,” while “white-box attacks are more useful for system developers to understand the limitations of the machine learning system and improve robustness during system training.”
There is also another type of attack called a data poisoning attack.
In some situations, attackers gain access to the dataset used to train the machine learning system. In these cases, attackers may implement a technique called “data poisoning,” where they deliberately introduce vulnerabilities into the system during the training phase.
For example, an attacker could train a machine learning system to be secretly sensitive to a specific pattern of pixels, and then distribute it to developers for integration into their applications without their knowledge. Given the costs and complexity associated with developing machine learning algorithms, the use of pre-trained systems is widespread in the AI community. Once the system is distributed, the attacker exploits the vulnerability to attack the applications that have integrated it.
2. Security in AI
AI Protection method : Adversarial Training
In recent years, artificial intelligence researchers have developed various techniques to strengthen the robustness of machine learning systems in the face of adversarial attacks. The most recognized defense method is “adversarial training,” where developers patch vulnerabilities by subjecting the machine learning system to examples of adversarial data during training.
With this approach, the designers of a model generate many adversarial examples to confront the model with these special cases, thus allowing the system to adjust and not reproduce these errors in the future.
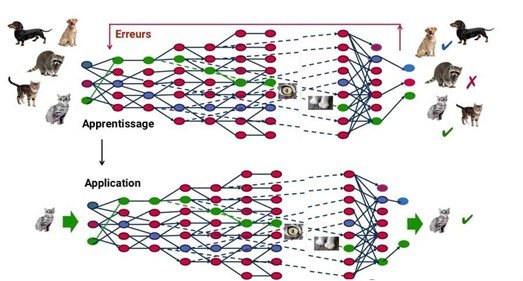
This approach is based on deep learning, a form of artificial intelligence derived from machine learning, where the machine simply rigorously applies pre-established rules. Using an artificial neural network inspired by the functioning of the human brain, made up of hundreds of layers, with each layer receiving and interpreting information from the previous layer, the system is able to first recognize letters before processing words in a text, or even determine the presence of a face in a photo before identifying the person concerned.
At each step, the “wrong” answers are eliminated and sent back to the upstream levels to adjust the mathematical model. Gradually, the program reorganizes the information into more complex blocks. When this model is then applied to other cases, it can recognize a cat without ever having been explicitly taught the concept of a cat. Initial data is crucial: as the system accumulates various experiences, its performance improves.
Limitations of this method
While this approach is effective, it is insufficient to counter all attacks due to the diversity of possibilities, not all of which can be anticipated. Thus, it is a race between the attackers who generate new strategies and the designers who train the models to make them immune to these attacks.
In other words, building an exhaustive theoretical model to anticipate these examples is virtually impossible. This would be tantamount to solving extremely complex optimization problems, for which we do not have the necessary theoretical tools.
AI Protection Method: Gradient Masking Techniques
As previously mentioned, some attack techniques exploit the gradient of an image. In other words, attackers take an image of an aircraft, test which direction in the image space increases the likelihood that the image will be recognized as a cat, and then disrupt the entry in that direction by altering its gradient. The newly modified image is thus falsely identified as that of a cat.
However, what would happen if there was no gradient, i.e. if a change in the image did not cause any change? This situation seems to offer some defense because the attacker would not know which way to orient the image.
We can easily devise very trivial ways to get rid of the gradient. Most image classification models can operate in two modes: a mode where they produce only the identity of the most likely image, and a mode where they generate probabilities. If the image is identified as “99.9% airplane, 0.1% cat”, then a slight change in the input results in a slight change in the output, and the gradient indicates which changes will increase the likelihood of having a cat. On the other hand, if the model is run in mode where the output is detected only as an airplane only (the most likely identity only), then a small change in the input will not change the output at all, and the gradient will provide no indication.
Here’s how to explain this method:
We can all agree that this image is clearly of an aircraft. At first glance, we can say this with 100% certainty.
Now, let’s imagine that our image classifier model works in probabilistic mode.
When we present it with the image of the aircraft as input, here is the output result:
99.9% avion, 0,1% chat

Now, let’s randomly add a few pixels to see how this might alter the output of our classifier:
+ .007 x

Now the output is as follows:
90 % avion, 10 % chat.
With these results, the attacker can determine the “direction of space” in which to disrupt the entry by adding pixels to increase the likelihood that the image will be identified as a cat.
Next, let’s imagine that our image classifier works in “most likely image” mode, without the notion of gradient. Let’s present him with the image of the plane again. The output of the classifier, without the notion of gradient, will only provide the most likely result:
Airplane.
By adding pixels to the input:
+ .007 x

Since the most likely outcome remains “airplane” in this case, the output remains unchanged. So the attacker doesn’t have the ability to figure out how to tamper with the input to fool our classifier.
Limitations of this method
While this method may offer some defense, it is not foolproof. This is because an attacker could build their own model, a gradient-based model, manipulate images for their model, and then deploy those examples against the target model. In many cases, the target model would be trapped.
In other words, the attacker trains a substitution pattern: a copy that mimics the target model by observing the outputs of the target model for inputs carefully chosen by the attacker. This is how it could bypass gradient masking.
AI Protection Method: Input Control
The input control method, also known as data augmentation, is a combination of various techniques to artificially increase the amount of data by generating new points from existing data. This can include slight changes to existing data or the use of deep learning models to create new points. This approach aims to improve the accuracy of the model’s predictions.
Most data augmentation techniques focus primarily on simple visual changes.
We can talk about:
- Padding
- Random Rotation
- Re-scaling
- Vertical and horizontal flipping
- Cropping
- Zoom
- Darkening and Brightening/Changing Colors
- Grayscaling
- Changing Contrast
- Adding Noise
- Random Erase
Limitations of this method
This method is effective except in cases where data are restricted. This is because in these situations, crucial information may be missing, especially from data not used during training, which can lead to biased results.
AI Protection Method: Distillation
Defensive distillation is a training method to strengthen the resilience of a classification algorithm, thereby reducing its vulnerability to exploitation. This approach consists of training a model to predict the output probabilities of another model previously trained on a standard basis, thus increasing the accuracy of the process.
When a model is trained to achieve maximum accuracy, such as with a probability threshold of 100%, it may have shortcomings because the algorithm does not process every pixel for time reasons. If an attacker learns what features and settings the system is scanning, they could send an incorrect image with only the relevant pixels to fool the model.
In the case of distillation, the first model indicates a 95% probability that a fingerprint will match the biometric analysis recorded. This uncertainty is then used to train a second model, acting as an additional filter. With the introduction of a random element, the second algorithm, also known as the “distilled algorithm”, becomes much more robust, making it easier to detect spoofing attempts.
Limitations of this method
The main disadvantage of this approach is that, although the second model has more flexibility to reject an attacker’s manipulations, it is still constrained by the general rules of the first model. So, with enough computing power and proper adjustments on the attacker’s part, both models can be reverse-engineered to uncover fundamental vulnerabilities.
In addition, distillation models are prone to poisoning attacks, where the initial training database can be corrupted by a malicious actor.
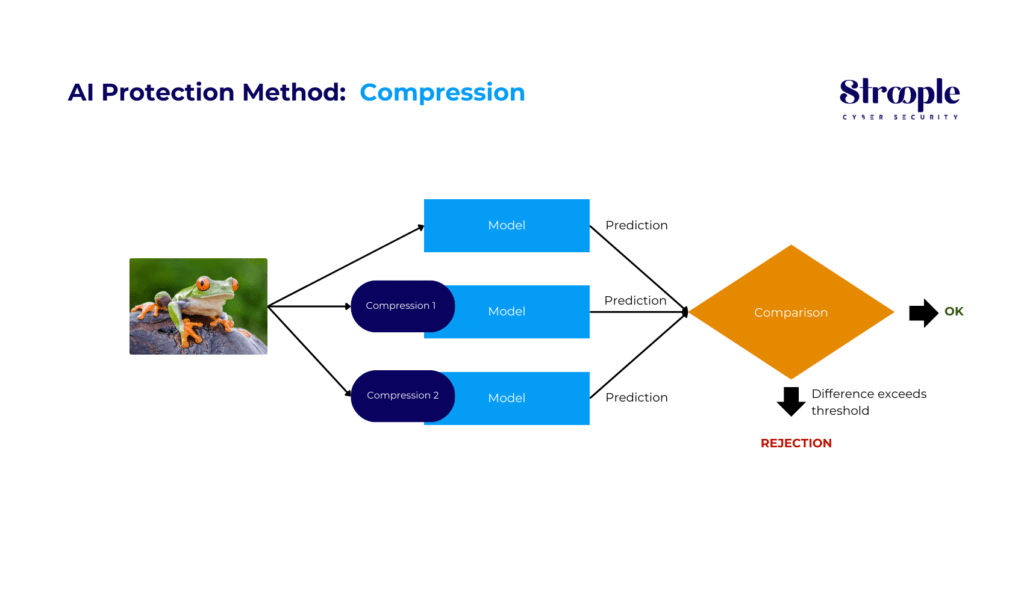
AI Protection Method: Compression
The compression technique is effective in spotting adversarial attacks by compressing an input in various ways and subjecting it to the same pattern. The results obtained are then compared, and if the compressed inputs generate significantly different outputs than the unmodified input, this indicates the detection of an attack.
By quantifying the disagreement between predictions and establishing a threshold, our system generates accurate predictions for legitimate examples while rejecting input from an attack.
Limitations of this method
This approach is only effective against static attackers who don’t adjust to directly target the compression method. However, if attackers are able to adapt, they can identify an input that produces incorrect output while maintaining a comparison score between the model predictions for compressed inputs and the uncompressed input below the detection threshold.
In conclusion, the rapid evolution of artificial intelligence has revolutionized many aspects of our daily and professional lives. However, this technological advance is not without risks. As we’ve seen, AI is susceptible to a multitude of security vulnerabilities, ranging from adversarial attacks to data poisoning. Current defense methods, such as adversarial training, gradient masking techniques, input control, distillation, and compression, offer partial and specific solutions, but none of them is a panacea.
In the face of these challenges, it is clear that security in AI is an ever-evolving field, requiring constant vigilance and innovation. Researchers and developers must continue to collaborate to design more robust and secure AI systems. At the same time, it is imperative to develop a deeper understanding of AI vulnerabilities to effectively anticipate and counter new threats.
The future of AI will largely depend on our ability to secure its foundation and educate users about potential risks. By taking a proactive approach and investing in security research and development, we can hope to successfully navigate this complex maze of vulnerabilities, ensuring a safer and more trustworthy future for artificial intelligence.
In the face of these ever-changing challenges, it is essential to surround yourself with cybersecurity experts. Stroople, as a pure player in the field of cybersecurity, positions itself as the trusted partner to support its customers in securing their digital activities in the face of the rapidly evolving cyber threat.
